HarryData大數據操作系統 驅動政務服務創新與信息系統運維升級
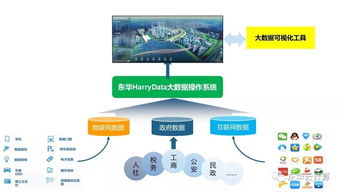
隨著數字化轉型的深入,政務服務領域正經歷著從信息化到智能化、精準化的深刻變革。在這一過程中,大數據操作系統作為核心基礎設施,發揮著至關重要的作用。HarryData大數據操作系統,憑借其強大的數據集成、處理、分析與服務能力,為政務服務現代化注入了新動力,同時也對傳統的信息系統運行維護服務模式提出了新的要求并帶來了升級機遇。
一、HarryData在政務服務中的核心應用場景
- 數據資源整合與“一網通辦”:政務服務涉及公安、社保、稅務、市場監管等多個部門,數據孤島現象曾長期存在。HarryData大數據操作系統能夠打破壁壘,實現對跨部門、多格式、海量政務數據的統一接入、標準化治理與融合管理。這為“一網通辦”、“跨省通辦”提供了堅實的數據底座,使公民和企業能夠通過一個入口辦理多項業務,極大提升了辦事便利性和政府服務效率。
- 精準決策與科學治理:通過對經濟運行、社會民生、城市運行等領域的多維度數據進行實時分析與深度挖掘,HarryData能夠幫助政府管理者洞察發展趨勢、識別潛在風險、評估政策效果。例如,在宏觀經濟調控、公共衛生事件預警、智慧城市建設規劃等方面,提供數據驅動的決策支持,推動治理模式從經驗判斷型向數據分析型轉變。
- 個性化服務與主動推送:基于對用戶行為和歷史辦事數據的分析,系統能夠構建精準的用戶畫像,實現服務的個性化推薦和精準推送。例如,主動提醒市民辦理證件續期、推送符合其條件的惠民政策、為特定企業推薦合適的扶持項目等,變“人找服務”為“服務找人”,增強民眾的獲得感和滿意度。
- 強化監管與風險防控:在市場監管、金融風險、社會保障基金監管等領域,HarryData能夠通過構建風險模型,實時監測異常模式,實現從事后查處到事前預警、事中干預的轉變,提升監管的精準性和有效性,維護公平有序的市場環境和社會穩定。
二、對信息系統運行維護服務的變革性影響
HarryData大數據操作系統的引入,使得政務信息系統從相對封閉、穩定的傳統架構,轉向開放、復雜、動態演進的大數據平臺架構。這對運行維護服務提出了全新的挑戰和要求:
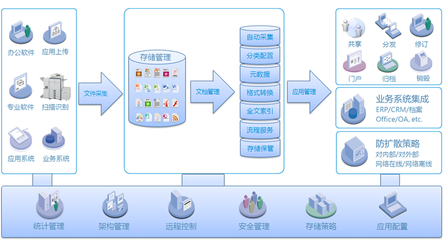
- 運維對象的復雜化:運維范圍從原有的應用服務器、數據庫,擴展到涵蓋海量數據存儲(如HDFS)、分布式計算框架(如Spark、Flink)、數據采集工具、數據治理平臺、數據API服務等一整套大數據技術棧。運維人員需要具備大數據領域的專業知識。
- 運維模式的主動化與智能化:傳統“救火式”的被動運維難以為繼。基于HarryData平臺自身的監控能力和運維數據,需要構建智能運維(AIOps)體系。通過采集平臺及應用的性能指標、日志、鏈路追蹤數據,利用機器學習算法進行異常檢測、根因分析、容量預測和故障自愈,實現從“人工響應”到“自動預警與處置”的轉變,保障7x24小時數據服務的穩定、高效。
- 安全運維的極端重要性:政務數據涉及大量敏感信息和公民隱私,數據安全是生命線。運維服務必須建立涵蓋數據全生命周期(采集、傳輸、存儲、處理、交換、銷毀)的安全管控體系,包括嚴格的權限管理、數據脫敏、訪問審計、漏洞掃描與應急響應等,并需符合等保2.0等相關法規要求。
- 價值導向的運維服務:運維目標不再僅僅是“系統不宕機”,更要確保“數據能用、好用、管用”。運維服務需要與業務部門緊密協作,關注數據服務質量(如數據時效性、準確性、API響應速度)、數據資產健康度以及數據分析成果的業務價值實現,運維團隊的角色逐漸向數據運營支撐者轉變。
- 常態化數據治理運維:數據質量是數據分析價值的基石。運維服務需要將數據標準管理、元數據管理、數據質量稽核與整改等數據治理活動作為日常運維工作的一部分,建立長效機制,確保流入HarryData平臺的數據是可信、可用的。
三、未來展望:構建一體化、智能化的政務數據運維新生態
以HarryData為代表的政務大數據平臺將與云計算、人工智能、物聯網等技術更深融合。信息系統運行維護服務需要與時俱進,構建“平臺運維+數據運維+安全運維+智能運維”的一體化服務體系。通過建立專業的大數據運維團隊,制定標準化的運維流程和預案,部署先進的運維工具平臺,最終實現政務大數據平臺的穩定、安全、高效運行,從而持續釋放數據要素價值,賦能服務型政府與數字社會建設,讓政務服務更聰明、更貼心、更有溫度。
如若轉載,請注明出處:http://www.xiuliu.com.cn/product/53.html
更新時間:2026-06-18 18:55:38